¶ Триггер поиска текста
Триггер поиска текста использует движок OCR Tesseract, чтобы извлекать текст из захваченного изображения. Благодаря этому EyeAuras может реагировать на определенные фрагменты текста в игре или приложении — от автоматических действий на игровые события до более сложных сценариев и скриптов.
¶ Обзор Tesseract
Tesseract — это движок оптического распознавания текста, изначально разработанный в HP, а сейчас поддерживаемый Google. Он отличается высокой точностью и поддерживает распознавание нескольких языков, поэтому отлично подходит для извлечения текста из изображений.
¶ Параметры захвата
Они такие же, как и в других триггерах поиска по изображению. Подробнее см. на этой странице.
¶ Выражение для сопоставления текста
Вы можете задать собственное выражение для проверки распознанного текста, используя все возможности Text Match Expressions.
¶ OCR-движки
EyeAuras использует следующие движки для преобразования изображений в текст:
- Tesseract — одно из лучших open-source решений, но в какой-то момент оно стало уступать варианту через Windows API. Вы можете установить дополнительные языки, скачав файлы языков и поместив их в нужную папку — подробнее см. в разделе ниже.
- Windows OCR — использует встроенные возможности Windows для OCR. Для нужного языка должен быть установлен соответствующий языковой пакет. Например, если вы хотите распознавать русский текст, в Windows должен быть установлен русский языковой пакет. Подробнее см. в разделе ниже.
¶ Символы
Этот параметр позволяет указать язык, который будет использоваться для распознавания. По умолчанию в EyeAuras встроены четыре модели:
- Windows (language): распознает символы выбранного языка и арабские цифры
- Tesseract (eng+rus): распознает и русские, и английские символы, а также цифры
- Tesseract (eng) / Tesseract (rus): распознает только английские или только русские символы
- Tesseract (numbers): распознает только цифры
¶ Windows OCR: включение поддержки OCR для определенного языка в Windows 10+
Откройте Settings:
- Нажмите кнопку Пуск Windows в левом нижнем углу экрана.
- Нажмите на значок шестеренки — “Settings”.
Перейдите в настройки языка:
- В окне Settings откройте раздел “Time & Language”.
- Затем выберите “Language” в левой панели.

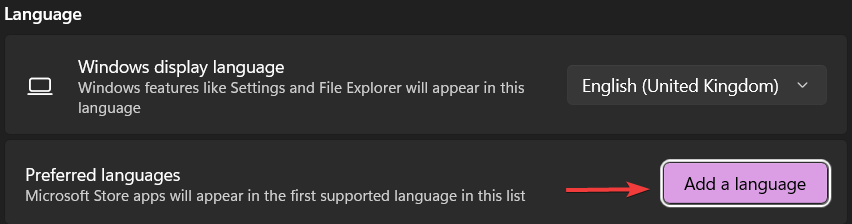
Добавьте новый язык, если он еще не добавлен:
- В разделе 'Preferred languages' нажмите кнопку “Add a preferred language”.
- Откроется окно со списком языков. Можно прокрутить список вручную или ввести название языка в строку поиска сверху.
- Когда найдете нужный язык, нажмите на него, затем нажмите “Next”.
- Убедитесь, что включена опция “Install language pack”, и нажмите “Install”.
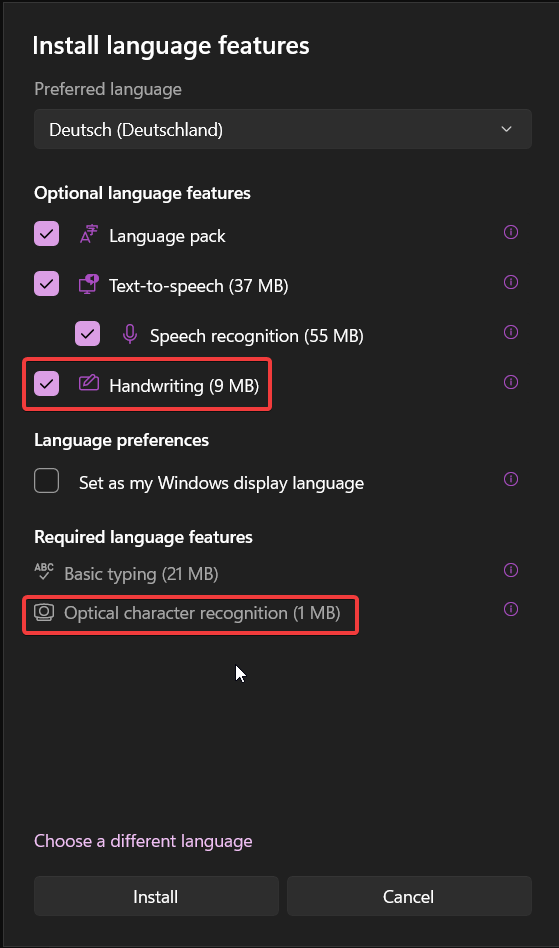
Установите OCR Language Pack:
- Когда нужный язык появится в списке 'Preferred languages', нажмите на него.
- Затем нажмите “Options”.
- В разделе “Download” вы увидите доступные компоненты для этого языка. Найдите “Handwriting” или "Optical Character Recognition (OCR)" и нажмите кнопку “Download” рядом с ним.
Дождитесь завершения установки:
- Windows скачает и установит необходимые файлы для OCR на выбранном языке. Это может занять некоторое время в зависимости от скорости интернета.
Проверьте установку:
- После завершения статус должен измениться на “Installed”. После этого окно Settings можно закрыть.
Перезапустите приложение:
- Если EyeAuras уже открыт, закройте и запустите его заново, чтобы программа увидела новые OCR-возможности.
¶ Tesseract: добавление пользовательских языков
EyeAuras использует следующий подход для загрузки моделей Tesseract: приложение загружает модели по умолчанию и позволяет добавлять собственные. EyeAuras ищет файлы языковых данных Tesseract с расширением **.traineddata** в каталоге **%appdata%\release\tessdata**. Дополнительные модели Tesseract можно скачать из этого репозитория. Обратите внимание: после добавления новых моделей приложение нужно перезапустить.
¶ Как улучшить результаты поиска текста
Чтобы добиться наилучших результатов OCR, рекомендуется, чтобы текст на изображении был черным на белом фоне. Этого можно добиться несколькими способами:
Invert Image Options: инвертирует цвета изображения, превращая белый текст на черном фоне в черный текст на белом фоне.
Binary Threshold: преобразует цветное изображение в черно-белое. Установленное пороговое значение определяет, что будет считаться черным, а что белым. Для Tesseract это значительно улучшает результат, для Windows — заметно меньше.
Scale factor: изменяет размер изображения с указанным коэффициентом. В некоторых случаях увеличение Scale Factor — единственный способ получить результат от OCR, особенно если изображение маленькое или текст написан нестандартным шрифтом.
Image Effects: позволяет изменить изображение так, чтобы оно лучше подходило для OCR. Например, можно настроить яркость, контрастность и насыщенность, чтобы сделать текст более различимым.
Помните: чем выше качество исходного изображения и чем сильнее контраст между текстом и фоном, тем точнее будет OCR.
¶ Применение в играх
- Отслеживание здоровья/маны: в играх, где здоровье или мана отображаются текстом, триггер может автоматизировать действия на основе этих значений, например использовать зелье здоровья, если HP упало ниже определенного уровня.
- Управление инвентарем: в играх, где инвентарь представлен в текстовом виде, как в старых RPG, Text Search Trigger может определять, когда получен или использован определенный предмет, и запускать нужные действия.
- Выбор реплик в диалогах: в играх с несколькими вариантами ответа Text Search Trigger может автоматически выбирать нужные варианты по тексту на экране.
- Оповещения в RTS: Text Search Trigger может отслеживать предупреждения или обновления по ресурсам в стратегиях в реальном времени и уведомлять игрока либо запускать нужные действия.
- Коммуникация в MMO: триггер может читать сообщения внутриигрового чата и запускать автоматические ответы на определенные фразы или ключевые слова.
- Инструмент доступности: для игроков с ограниченными возможностями Text Search Trigger может читать и интерпретировать текст на экране, упрощая действия, которые иначе потребовали бы более сложного ввода.
- Отслеживание квестов: в RPG триггер может считывать обновления квестов с экрана и автоматически отслеживать прогресс или переключать активные задания.
- Отслеживание достижений: триггер может распознавать уведомления о достижениях на экране, записывать их или запускать визуальные эффекты.